
How to… deal with Unwanted Characters
When cleaning data, individual characters that are not what you expect in your data fields can cause significant issues. Those issues cross between loading, using and outputting the data. Therefore, understanding what are unwanted characters, the issues they cause and how to remove them is a key skill in your cleaning arsenal of techniques.
What is an unwanted character?
An unwanted character can be simply covered as a letter, number or symbol within your data field that you neither require or causes issues by its presence. Data software is often very precise on what it is processing and rightly so, otherwise erroneous answers could easily be produced. Let's handle the three main types of data fields that get affected by unwanted characters when bring that data into Tableau Prep:
Numeric fields - if a non-numeric character enters a numeric field, the field can no longer be used in aggregations as the data field will be absorbed in as a string. For example, what should 10 + 1c3 equal? Simply, it can't be done and therefore a numeric .
Dates - if a non-numeric character enters a date data value where it is expected, the date value with the unwanted character will appear as a null as the date will be in an invalid form.
String - Strings are very flexible data types and therefore, won't error when trying to bring strings with unwanted characters. The only time the string fields may error is where a character is used outside those that are allowable by either the data source or Tableau Prep.
The most common unwanted space in data preparation is the humble space. The 'space' between characters is easily spotted visually but not so with a leading or trailing space. These still count as a character when using string functions like left, right, mid or split and therefore cause issues with most common string data preparation steps.
What issues are caused by unwanted characters?
Data preparation is the process where we take unusable data for analysis and turn it into data that is suitable for analysis so the challenge of unwanted characteristics isn't very different many others in data preparation. The difference with unwanted characters is that they pose potentially challenging individual values to clean rather than entire data fields. Identifying those individual values with the unwanted characters can be a challenge especially in a string field as the field doesn't simply turn to nulls on input.
The main issue with unwanted characters is that you can't prepare a data field as you might like to as the unwanted character might prevent you from applying a single preparation rule to all values in the data field. Therefore, a numeric field with a hidden non-numeric can be simply aggregated preventing many of the common steps from working as normal. Instead of playing a game of 'spot the needle in the haystack' by visually searching through a data field and all of its values for the unwanted character, it's better to use some of the functionality within Prep to assist.
In the following example table, there is at least one unwanted character in each of the data fields to demonstrate the affects of their presence. The data set is a comma separated value (csv) file:

Tableau Prep Builder loads a csv file's data fields as string fields. Therefore, users will always need to set the data types in Tableau Prep before using data type specific functions:
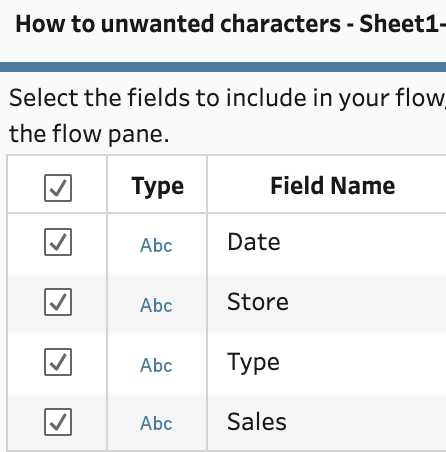
By changing the different fields into the data type they would need to be in for analysis, the unwanted characters creates the issues highlighted above. Date values that do not conform to the expected date format are turned to nulls:
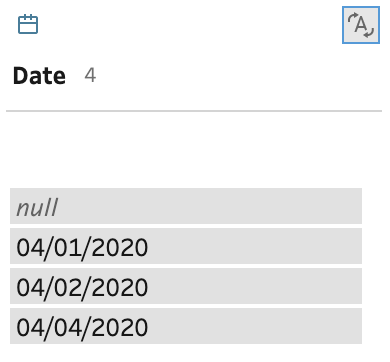
The Sales figures that are not solely numeric are turned into nulls:
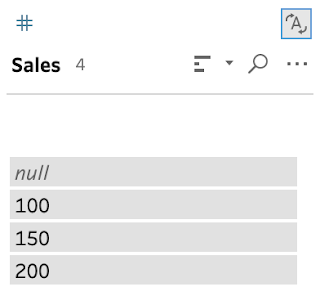
The string values with the additional exclamation mark, or number 8, remain as strings but clearly the values are different so are split apart in the profile pane.
Therefore, to make the data usable, the answer can't not be doing nothing as valuable data is likely to be lost. Therefore, the removal of the unwanted characters is what is required.
Removing unwanted characters
Depending on the character and the data type the field should be, the action taken to remove the unwanted character will alter.
Strings with mistyped characters
With free text entry, words and names can easily be mistyped by individual entering the information. Often, the values being entered are close enough to other similar values that Prep's 'Group and Replace' functionality can amend the unwanted character, whatever it maybe, to the correct characters.
To use this technique, find the '...' icon of the string data field and select 'Group and Replace' followed by 'Spelling'.

This results in just a single value for Clapham and the correct spelling is taken from the most common result. The same technique can be applied where numbers are used instead of letters, like the bar example. The resulting data set after the grouping technique is applied to both columns is a single name in each column rather than the two values in each before:

Numbers with unwanted characters
When converting the Sales field to a numeric data type, the value with the letter leading it causes the value to result in a null. To resolve this, we can use Prep's cleaning functionality also in the '...' menu:

Here we find the option to remove letters from the data field before converting the data field to a numeric data type:
This results in a set of values that are what we want for the analysis:

Dates with mistyped characters
If there are additional characters, the cleaning technique to remove the characters as per the Numbers with unwanted characters can be used. If the character is mistyped, there probably needs to be some human logic to determine what the actual value should be. You can search manually but in large data sets this can take a significant amount of time. Instead regular expressions can be used to find the unwanted characters, in this case a letter. The following calculation returns true when a letter is found in the date field:

This results in a clear indicator when a letter appears somewhere within the string field. The profile pane helps identify the values that are affected:

A manual assessment can then be made for how to resolve the issue. In this example data set, I expect to have a record per date so clearly the '0c' needs to be renamed as '03'. This can be done with a quick manual rename. Do this by double :
The data type can then be changed to date without turning any values to null.

Summary
Unwanted characters can be quite challenging when preparing data. These challenges can be largely handled by built in functionality within Tableau Prep. Sometimes more bespoke rules will need to be created to help to identify the issue and then manual fixes to resolve the issue.