
How to… deal with String data
When I think about preparing data, I instantly think about battling fields that contain string data. Customer names, product descriptions, messages and geographic names are all types of data that you will likely need to manipulate when you prepare your data for analysis.
What do we mean by strings?
When most people think of data, they think about the measures we are summing, averaging or simply finding the largest value. But those measures don't tell us much until we start analysing things at different levels, ie: Average Sales by Region or Total Sales per Company.
Strings are often those dimensions that we are cutting the data by in tools like Tableau. Strings are shown in Tableau with the 'Abc' icon.

String fields in Tableau are shown by the 'abc' icon
String data fields are the most flexible in terms of the values you can hold within them. Typically, everything from A-z and 0-9 as well as punctuation and most others characters can all be found within them. With that flexibility also comes the pain in data preparation as the variety of values can create headaches!
Why is working with string data different?
When cleaning string fields, we approach them very differently to numeric fields. When we analyse string data fields, the order of the characters is very important. We look at which character is in which 'position' in the string. Here's an example with Preppin' Data:

We can see the first letter in the string is a capital 'P' when counting from the left. We will come back to the counting of the letters in a certain direction later. Let's look at some other facets of the string:
The last letter is in the 13th position from the left and is a lower case 'a'
The ' (quote mark or inverted comma) counts as having a position in the string
The space also has a position allocated to it in the string
What are the common challenges with string data?
Names
Splitting - Sometime names are in one column (field) of data and you need them to be in two separate columns. You would therefore want to split the name field in to separate columns. This can be challenging as names are often different lengths. Some people have two, three or four names so becomes harder to designate surname / family name.
Initials - If you have a full first name in your data set, you may only want the first initial.
Changing Case
UPPER / lower - Many data tools are case sensitive. This means that you won't be able to match THIS and this or This. The software will see these records as being different. Making all the string fields similar is important when Grouping your data together or Joining different data sets with different Cases.
Title Case - This is more tricky as not every piece of software has a simple Title Case function. The first letter in each word will be in Upper Case with every subsequent letter being in lower case.
Addresses
Names - Like people's names, City Names, Country names can often be held differently as geographical areas change over time. Ensuring you are comparing like-for-like can often be a significant challenge.
Address Lines - when filling out my address on a form, I often find that I enter the details slightly different every time. Whether a form has Company Name or Address Line 1/2 makes a significant difference to my data entry. To process this data consistently can be a significant challenge.
Postcodes in the UK - This is one area the US definitely beats the UK on - postal codes. The UK's postcodes can come in multiple forms like: AA1 1AA or A1 1AA or A1A 1AA. Trying to piece these together along with the space sometimes disappearing cane be a significant challenge.
Removing Spaces
When matching strings, it isn't just about cases that should concern you but characters that you can't even see on the screen. Often when splitting data or depending on method of entry, a space maybe lurking at the end of the word, or alternatively at the start. These are very difficult to check for but data software developers have given us a handy function to counter this with.
Poor / Inconsistent Spelling
This can take many forms but is often a result of poor planning when setting up IT systems or not thinking about the data analyst who will enivitably get asked to analyse the data a system spits out. This challenge can be simple or migraine inducing.
What functions will you frequently use when preparing string data?

Split - breaking up longer strings of data in to shorter strings based on a specified character.
Trim - removes the leading or trailing spaces from any given field
Upper / Lower - Will change every alphabetic character in to either an upper or lower case letter.
Left / Right - Will take a specified number of characters from either the left or right side of the string depending on which function is used
Mid - takes the next specified characters from a certain position in a string. Coupled with find or findth, this can be a powerful function.
Find - finds the first instance of a character in a string. You get to specify the character.
Findnth - finds the 'nth' instance of a character in a string.
It's not just calculated fields that will help you to prepare strings
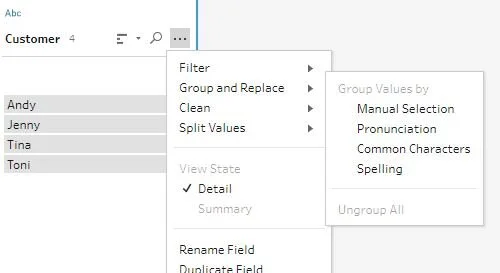
In Tableau Prep, the grouping functions have gone beyond the Desktop version of the tool and can assist much faster clean-up of messy data sets. Grouping isn't just by manual selection as it is in Desktop but there are three alternative modes when working with strings:
Pronunciation - based on how syllables sound when put together
Common Characters - strings that have similar letters will be grouped together
Spelling - based on a correct spelling, similar words will be put together with either a missing or different letter
__________________________________________
If you want to practice these skills, here are some of the challenges that relate to this subject: